What is AIOps?
Big data, modern machine learning, and other advanced analytics technologies are used in AIOps platforms to improve IT operations (monitoring, automation, and service desk) functions directly and indirectly by providing proactive, personalized, and dynamic insight. Multiple data sources, data collection methods, analytical (real-time and deep) technologies, and presentation technologies can all be used at the same time with AIOps platforms.

The definition of AIOps is fluid because it is an emergent space. However, the following are the key elements:
- AIOps’ Components
- Learning from Computers
- Baselining performance
- Detecting an anomaly
- Root cause analysis that is automated
- Insights into the future
What is MLOps?
MLOps is a set of practices for data scientists and operations professionals to collaborate and communicate. The use of these practices improves the quality of Machine Learning and Deep Learning models, simplifies the management process, and automates their deployment in large-scale production environments. Models can be more easily aligned with business needs and regulatory requirements.
MLOps is gradually becoming a stand-alone approach to ML lifecycle management. Data collection, model creation (software development lifecycle, continuous integration/continuous delivery), orchestration, deployment, health, diagnostics, governance, and business are all covered.
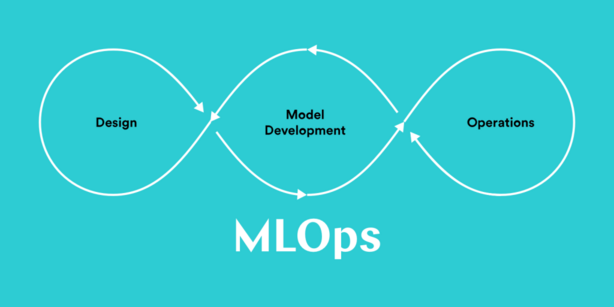
The following are the stages of MLOps:
- Obtaining information
- Analyzing data
- Transformation and preparation of data
- Model development and training
- Validation of models
- Serving as an example
- Monitoring of the model
- Model retraining
What is DataOps?
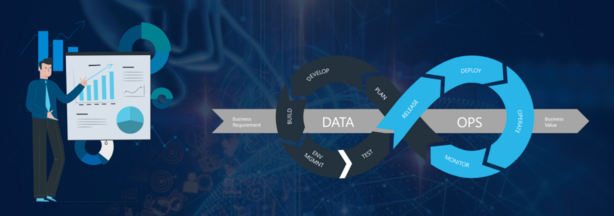
An organization’s collection of technical practices, workflows, cultural norms, and architectural patterns surrounding how they integrate their data assets into their business goals and processes is referred to as DataOps, an umbrella term. This means that each company’s data pipelines will be set up differently, but DataOps efforts in general aim to enable four capabilities within the company:
1. Delivering data insights to users and customers through rapid innovation, experimentation, and testing.
2. Improve data quality by reducing error rates to a minimum.
3. Coordinated collaboration among people, environments, and technologies.
4. Data pipelines are monitored in real time to ensure accurate measurements and transparent results.
What is GitOps?
GitOps is an operational framework that applies DevOps best practices for application development to infrastructure automation, such as version control, collaboration, compliance, and CI/CD tooling. While the software development lifecycle has become increasingly automated, infrastructure continues to be a largely manual process requiring specialized teams. With the increasing demands on today’s infrastructure, infrastructure automation has become increasingly important. Modern infrastructure must be able to manage cloud resources effectively in order to support continuous deployments.
Modern apps are built with speed and scalability in mind. Code can be deployed to production hundreds of times per day in organizations with a mature DevOps culture. Development best practises such as version control, code review, and CI/CD pipelines that automate testing and deployments can help DevOps teams achieve this.
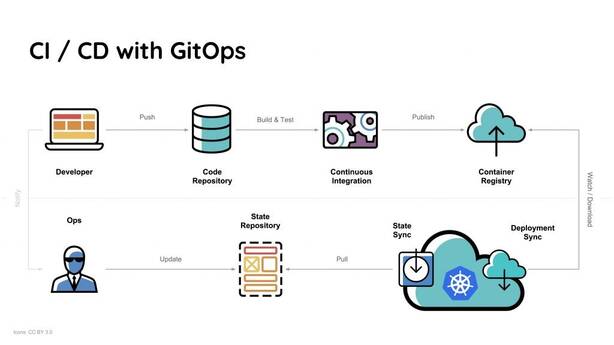
The provisioning of infrastructure is automated using GitOps. Teams that use GitOps use configuration files stored as code, similar to how they use application source code (infrastructure as code). The same infrastructure environment is generated by GitOps configuration files every time it is deployed, just as application source code generates the same application binaries every time it is built.
Differences between AIOps, MLOps, DataOps and GitOps:
| AIOps | MLOps | DataOps | GitOps |
| The use of big data analytics, machine learning (ML), and other artificial intelligence (AI) technologies to automate the identification and resolution of common IT issues is referred to as artificial intelligence for IT operations (AIOps). | MLOps is defined as “a practise for data scientists and operations professionals to collaborate and communicate to help manage the production ML (or deep learning) lifecycle.” | DataOps is a collaborative data management practice aimed at improving data flow communication, integration, and automation between managers and data consumers within an organization. | GitOps is a philosophy or set of practices that allows developers to take on tasks that would normally be handled by IT operations. GitOps requires us to use declarative specifications to describe and observe systems, which will eventually form the foundation of continuous everything. |
| AIOps automates IT operations processes such as event correlation, anomaly detection, and causality determination by combining big data and machine learning. | MLOps is a set of practises for data scientists and operations professionals to collaborate and communicate. The use of these practises improves the quality of Machine Learning and Deep Learning models, simplifies the management process, and automates their deployment in large-scale production environments. | DataOps (data operations) is a method for developing and delivering analytics that is agile and process-oriented. It brings together DevOps teams with data engineers and data scientists to provide the tools, processes, and organisational structures needed to support data-driven businesses. | GitOps ensures that the cloud infrastructure of a system can be quickly replicated based on the state of a Git repository. Pull requests make changes to the Git repository’s state. The pull requests will automatically reconfigure and sync the live infrastructure to the state of the repository once they have been approved and merged. |
| Through the scalable ingestion and analysis of the ever-increasing volume, variety, and velocity of data generated by IT, AIOps platforms combine big data and machine learning functionality to support all primary IT operations functions. Multiple data sources, data collection methods, and analytical and presentation technologies can all be used at the same time on the platform. | MLOps is well positioned to address many of the same issues that DevOps addresses in the software engineering world. DevOps addresses the issues that arise when developers hand off projects to IT Operations for implementation and maintenance, while MLOps offers data scientists a similar set of advantages. Data scientists, machine learning engineers, and app developers can use MLOps to focus on collaboratively delivering value to their customers. | DataOps is an automated, process-oriented methodology that analytic and data teams use to improve data analytics quality and reduce cycle time. The merging of software development and IT operations has improved software engineering and deployment velocity, quality, predictability, and scale. | The desired state of the system must be stored in version control so that anyone can see the entire audit trail of changes, according to GitOps. All commits that change the desired state are fully traceable, with committer information, commit IDs, and time stamps. |
| AIOps’ ultimate goal is to enable IT transformation and allow IT to operate autonomously. IT organisations can gain unified event intelligence, reduce noise in IT data and eliminate toil, reduce IT ticket volume, resolve IT problems faster, predict/prevent outages before they affect customers, automate root cause analysis, speed incident or problem resolution, improve IT productivity, and lower TCO using AIOps tools. | An MLOps team’s goal is to automate the integration of machine learning models into the core software system or as a service component. This entails automating the entire ML-workflow process without the need for manual intervention. | The goal of DataOps is to turn big data into business value. The DataOps strategy, which is based on the DevOps movement, aims to accelerate the development of applications that use big data processing frameworks. | The goal of GitOps is to make the development process easier and more efficient. This leads to the creation of repeatable infrastructure with proper state management, which improves both overall visibility and reproducibility. Reduces the application infrastructure’s management overhead. |