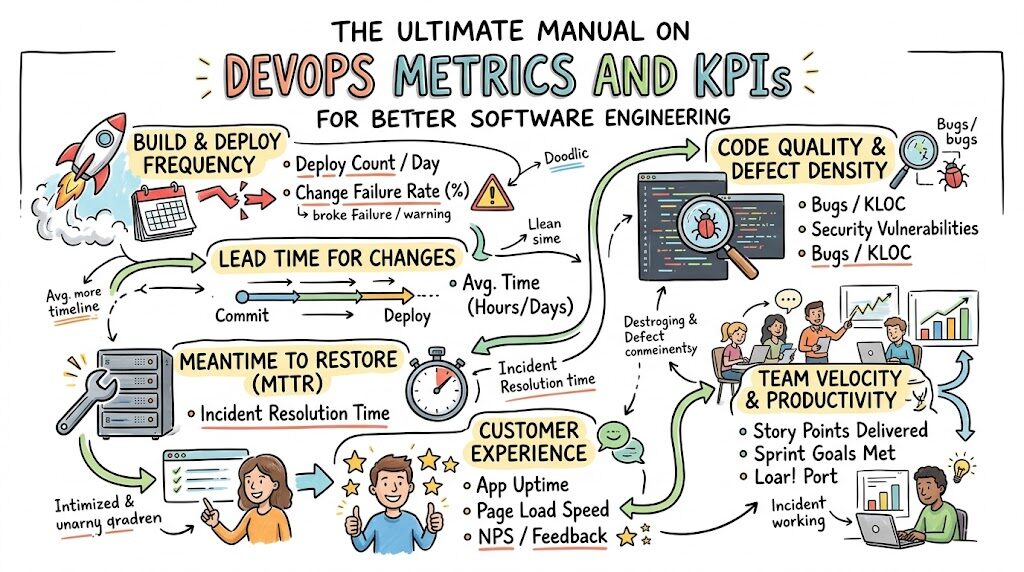
Introduction
Imagine navigating a massive commercial aircraft across the ocean during a stormy night without a single instrument panel in the cockpit. You have no altimeter to gauge your height, no fuel gauge to track consumption, and no radar to detect incoming obstacles. You are flying entirely on intuition, guesswork, and hope.
In the software development landscape, operating a release pipeline without tracking data feels identical. Engineering organizations frequently deploy code blindly, wondering why production environments crash, why development velocity stalls, or why software updates take months instead of days to reach end users.
This is exactly where data-driven engineering decisions become mandatory. Modern software engineering is no longer just about writing code; it is about delivering value to users reliably, securely, and quickly. Without concrete operational data, engineering leadership and development teams cannot determine whether their processes are improving or deteriorating over time.
For beginners entering the cloud computing and systems engineering ecosystems, the sheer volume of telemetry data can be overwhelming. Beginners frequently get confused by the overlapping terminologies of metrics, key performance indicators, service level objectives, and logging infrastructure. It is common to mistake raw systems data for operational success or to get buried under hundreds of automated alerts that lack business context.
Transforming a chaotic development workflow into a high-performing release pipeline requires a structured approach to measurement. By studying foundational monitoring and engineering practices through platforms like DevOpsSchool, professionals can learn how to convert raw infrastructure logs into actionable operational insights. Proper measurement changes the culture of an organization from reactive fire-fighting to proactive system optimization, allowing teams to deliver exceptional digital experiences at scale.
What Are DevOps Metrics?
DevOps metrics represent the fundamental, objective technical data points collected from systems, pipelines, and workflows across the software development lifecycle. These values are absolute numbers, rates, durations, or percentages that reveal the precise behavior of software applications, continuous integration pipelines, and infrastructure environments.
The central purpose of a metric is to capture raw operational performance data without bias. These measurements offer a granular look at the health of a technical ecosystem at any given second. For example, tracking how long a continuous integration server takes to run unit tests provides a technical metric that developers can use to optimize their testing suites.
In a practical workplace environment, technical teams configure automated tracking mechanisms within their version control systems, deployment pipelines, and cloud environments to gather these metrics continuously. Common baseline metrics include:
- The number of build failures occurring inside a continuous integration pipeline per day.
- The total size of a container image compiled during a build step.
- The time elapsed from a developer pushing code to the repository until the build succeeds.
- The exact count of automated test cases executed during a deployment cycle.
These numbers serve as the underlying telemetry used by engineers to diagnose bugs, find bottlenecks, and verify that software code functions appropriately before it moves closer to the customer facing environment.
What Are KPIs in DevOps?
Key Performance Indicators (KPIs) are the high-level, strategic measurements used to evaluate how successfully an engineering department is achieving its core business objectives. Unlike raw metrics, which focus strictly on technical mechanics, KPIs connect engineering activities directly to business outcomes, user satisfaction, and organizational growth.
The primary function of a KPI is business alignment. A KPI filters out the background noise of hundreds of raw system metrics to present a clear picture of organizational health to stakeholders, directors, and business unit leaders. A KPI helps answer a fundamental question: Is our software engineering effort driving tangible value for the enterprise?
For instance, while a system metric might tell an engineer that the database response time is forty milliseconds, a business KPI will tell an executive whether the digital checkout system is meeting its target of 99.9% successful transactions during peak sales hours.
Practical examples of KPIs across enterprise engineering departments include:
- Release Velocity: The frequency with which new, stable business features are made available to consumers.
- Customer-Impact Incident Rate: The percentage of code deployments that result in service degradations noticed by the actual user base.
- Operational Cost Per Release: The financial expenditure incurred across cloud infrastructure providers relative to the volume of features deployed.
- Mean Time to Value: The total duration required for an initial product concept to be coded, verified, and placed into production to generate revenue.
By aligning technical actions with clear KPIs, engineering teams ensure that they are not just writing code quickly, but are actually building reliable systems that improve the enterprise’s bottom line.
DevOps Metrics vs KPIs
Understanding how to design a balanced tracking strategy requires a clear view of how raw technical metrics relate to high-level KPIs. While they rely on the same underlying data layers, their target audiences, scopes, and objectives are fundamentally distinct.
| Area | Metrics | KPIs |
| Primary Scope | Tactical, granular, and highly specific to individual components. | Strategic, high-level, and focused on broad business goals. |
| Target Audience | Developers, system administrators, and site reliability engineers. | Engineering directors, product owners, executives, and clients. |
| Data Nature | Raw counts, system logs, time durations, and raw technical rates. | Aggregated data points evaluated against specific target thresholds. |
| Action Context | Used immediately for troubleshooting, debugging, and system tuning. | Used for long-term planning, resource allocation, and strategy. |
| Example Value | CPU utilization is at 84% on virtual machine instances. | Monthly platform availability meets the target goal of 99.95%. |
To visualize this difference in a real production environment, consider an enterprise e-commerce platform. A software engineer views a dashboard containing a thousand different metrics, such as memory usage per microservice container, network packet drops, and individual SQL query execution speeds.
At the same time, the Vice President of Engineering reviews a dashboard containing three critical KPIs: the platform’s overall uptime percentage, the average time required to deliver a feature to market, and the percentage of customer orders processed without an error. The metrics provide the diagnostic raw data needed to achieve the targets established by the KPIs.
Why DevOps Metrics Matter
Implementing a rigorous measurement strategy across modern software engineering operations provides several clear structural advantages for teams and organizations.
Better Decision-Making
Without data, architectural discussions often degenerate into debates based on personal opinions or political influence within a corporate hierarchy. When a team tracks metrics, decisions are grounded in objective reality. If an architecture team claims that migrating a service to a new cloud framework will improve performance, the metrics from automated stress testing will either prove or disprove that hypothesis immediately.
Faster Delivery
Tracking operational metrics highlights the hidden wait states in a development cycle. Many organizations believe their developers are slow at writing code, but metrics often reveal that code sits idle for days waiting for manual security reviews or QA approvals. Visualizing these delays allows engineering managers to eliminate blockages and accelerate code delivery safely.
Reliability Improvement
High-performing software systems rely on consistent predictability. By tracking infrastructure and error metrics, engineering teams can spot subtle degradations, such as memory leaks or gradual latency increases, before they balloon into full-scale system outages that impact thousands of consumers.
Team Performance Visibility
Metrics give engineering leaders a realistic view of team capacity and systemic health without micro-managing individuals. Instead of tracking lines of code written by a single developer—which is a counterproductive vanity metric—leaders can view the collective throughput and stability of the entire delivery pipeline, fostering an environment of shared ownership and transparent collaboration.
Core DevOps Metrics Every Beginner Should Know
For those beginning their journey into modern operations, focusing on a small, universally recognized set of baseline measurements yields the highest educational and practical return.
| Metric | Why It Matters |
| Deployment Frequency | Measures how often code is successfully promoted to production environments, indicating pipeline agility. |
| Lead Time for Changes | Measures the duration it takes for a commit to travel from a developer’s machine to production, indicating efficiency. |
| Change Failure Rate | Tracks the percentage of production deployments that result in immediate degradation or require rollbacks. |
| Mean Time to Recovery (MTTR) | Evaluates how long an engineering team takes to restore normal services following a production outage or failure. |
Deployment Frequency
This metric measures the rhythm of your engineering pipeline. Low-performing organizations deploy code once every few months, resulting in massive, high-risk releases. High-performing organizations deploy code multiple times per day in small, decoupled increments, reducing the risk of blast radius failures.
Lead Time for Changes
This metric quantifies the efficiency of your continuous integration and continuous deployment pipelines. If it takes three weeks for a simple single-line bug fix to navigate from a developer’s branch through automated testing, staging environments, and into production, the pipeline has significant processing friction that requires optimization.
Change Failure Rate
Speed without stability is useless. The Change Failure Rate acts as a quality governor against pure speed. If a team boasts fifty deployments a day, but twenty of those deployments crash production and require emergency hotfixes, the delivery mechanism is broken. A low change failure rate demonstrates that automated testing processes are highly effective.
Mean Time to Recovery (MTTR)
In modern cloud native architectures, failure is inevitable. Hardware will degrade, cloud providers will experience network anomalies, and bugs will slip past test suites. MTTR measures a team’s resilience. It tracks the time from the initial detection of a production incident until the system returns to its baseline operational state.
Understanding DORA Metrics
The DevOps Research and Assessment (DORA) team, compiled over years of extensive industry research across thousands of global organizations, established four fundamental metrics that serve as the industry standard for evaluating software delivery performance. They are categorized into two primary pillars: speed and stability.
+-----------------------------------------------------------------+
| DORA METRICS |
+-----------------------------------------------------------------+
| |
[ SPEED PILLAR ] [ STABILITY PILLAR ]
| |
├── Deployment Frequency ├── Change Failure Rate
└── Lead Time for Changes └── Mean Time to Recovery (MTTR)
1. Deployment Frequency (Speed)
In a healthy enterprise workplace scenario, an elite engineering team utilizes extensive automation to push code to production continuously.
- Workplace Scenario: A financial technology team breaks down a large monolithic banking application into distinct microservices. Instead of waiting for a quarterly release window, developers merge pull requests daily. Automated validation suites run within fifteen minutes, and code is automatically deployed to production via blue-green deployment strategies, achieving multiple production releases per day.
2. Lead Time for Changes (Speed)
This metric spans the entire life cycle of a code modification, from the initial git commit timestamp to the successful execution of that code in the production cluster.
- Workplace Scenario: A software developer fixes an interface alignment bug on an e-commerce checkout page. The commit is logged at 09:00 AM. The automated testing pipeline builds the container, runs integration tests, executes security scans, and deploys the change to production by 10:30 AM. The lead time for this change is exactly ninety minutes, showing a highly responsive, low-friction pipeline.
3. Change Failure Rate (Stability)
This metric is calculated by dividing the number of deployments that cause an incident, crash, or severe performance degradation by the total number of deployments executed within a specific timeframe.
- Workplace Scenario: A team deploys one hundred updates to an API gateway over a month. Five of those updates introduce critical bugs that trigger automated rollbacks or require immediate hotfixes to prevent user downtime. The change failure rate for that month is exactly 5%. If this number spikes to 20%, the team knows they must pause feature development to fix their automated integration test coverage.
4. Mean Time to Recovery (MTTR) (Stability)
MTTR tests the maturity of an organization’s monitoring, alerting, incident response protocols, and deployment architecture.
- Workplace Scenario: At 02:00 PM, an underlying database connection pool exhausts its available threads, causing a user-facing banking platform to return 500 Internal Server Errors. Automated monitoring alerts the on-call SRE team at 02:02 PM. The SRE team analyzes the centralized metric dashboard, isolates the misconfigured service, and executes an automated script to scale the connection pool, restoring full system operation by 02:12 PM. The MTTR for this incident is twelve minutes.
Reliability Metrics in DevOps
Reliability metrics focus heavily on the operational stability and availability of systems from the standpoint of the end user. High delivery speed means nothing if the system is chronically unavailable or slow when customers attempt to access it.
Availability and Uptime
Availability represents the percentage of time a system remains operational, responsive, and capable of performing its intended functions over a defined measurement period. This is traditionally calculated using percentages known as “the nines”:
- 99% Uptime: Allows for roughly 3.65 days of total downtime per year.
- 99.9% Uptime: Allows for roughly 8.76 hours of total downtime per year.
- 99.99% Uptime: Allows for roughly 52.56 minutes of total downtime per year.
Error Rates
Error rates measure the ratio of failed requests against total requests processed by a system. In a typical web server configuration, this involves tracking the volume of HTTP 5xx series server-side errors relative to HTTP 2xx series successful responses. A sustained spike in error rates points directly to code defects or downstream infrastructure dependency failures.
SLA, SLO, and SLI Basics
Navigating reliability requires a firm grasp of the relationships between three critical concepts:
- Service Level Indicator (SLI): The precise, quantifiable measure of a service’s performance at any given moment. For example: “The percentage of HTTP requests completed successfully in under 200 milliseconds over the last rolling hour.”
- Service Level Objective (SLO): The target reliability goal agreed upon by internal engineering and product teams. For example: “Our platform’s SLI must hit at least 99.9% every calendar month.”
- Service Level Agreement (SLA): The formal, legally binding commitment made to external customers regarding system performance. Failing to meet an SLA results in financial penalties, refunds, or breach of contract consequences. For example: “The company guarantees 99% availability, or enterprise clients receive a 15% billing credit.”
Incident Management Metrics
When unexpected system anomalies manifest in production, incident management metrics help evaluate the coordination, responsiveness, and diagnostic capabilities of operations personnel.
Incident Frequency
This tracks the raw quantity of distinct unexpected service degradations or total failures occurring within a given operating window. A rising trend in incident frequency signals that technical debt is accumulating, meaning the codebase or infrastructure platform is becoming increasingly unstable.
Mean Time to Acknowledge (MTTA)
MTTA measures the elapsed time between an automated alert triggering within a monitoring framework and an on-call engineer explicitly flagging that alert within an incident response platform to begin remediation.
Important Operational Note: A long MTTA indicates alert fatigue, poorly configured notification pathways, or inadequate on-call staffing schedules. If engineers take an hour just to notice that a core service is failing, the alerting system is broken.
Mean Time to Resolution (MTTR)
While similar to the DORA MTTR variant, within incident management, this focuses broadly on the entire structural lifecycle of a crisis. This includes detection, triage, isolation, applying temporary workarounds or full code rollbacks, and validating that user sessions have stabilized entirely.
Consider a real-world example: A popular streaming service experiences an outage where video assets fail to load due to an expired SSL certificate on a content delivery network node. The time sequence unfolds as follows:
[04:00 PM] Outage Occurs ──> [04:02 PM] Alert Fires ──> [04:05 PM] Engineer Responds ──> [04:25 PM] Issue Resolved
| | |
+─────── MTTA: 3 Mins ─────+───────── MTTR: 23 Mins ──────+
- 04:00 PM: The certificate expires; users encounter playback errors.
- 04:02 PM: Automated monitors log a surge in failed connections and dispatch a high-severity page.
- 04:05 PM: The designated SRE responds to the page and begins investigation. (MTTA = 3 Minutes).
- 04:12 PM: The engineer identifies the expired asset and initiates a renewed certificate deployment.
- 04:25 PM: The certificate propagates globally, tests pass, and user traffic returns to normal. (MTTR = 23 Minutes from initial alert acknowledgement).
Infrastructure and Performance Metrics
Infrastructure metrics represent the foundational resource consumption telemetry pulled directly from virtual machines, physical servers, bare metal environments, and containerized runtimes.
+-----------------------------------------------------------------------+
| INFRASTRUCTURE METRIC MONITORING |
+-----------------------------------------------------------------------+
| | |
[ COMPUTE ] [ STORAGE ] [ NETWORK ]
| | |
├── CPU Usage └── Disk I/O └── Network Latency
└── Memory Allocation
CPU Usage
CPU utilization measures the processing capacity consumed by active software applications on a host machine. If a containerized application scales poorly and pins a server’s CPU capacity at 98% for extended intervals, incoming user requests will experience severe queuing, causing responses to stall or drop completely.
Memory Utilization
Memory allocation tracks the random-access memory (RAM) consumed by software runtimes. Unlike CPU usage, which can safely spike temporarily during heavy calculation periods, memory consumption that climbs linearly without ever dropping indicates a structural memory leak within the application source code. If left unaddressed, the operating system’s kernel will eventually invoke an Out-Of-Memory (OOM) killer process, abruptly terminating the application to preserve system integrity.
Disk Usage and Disk I/O
Disk usage tracks the storage capacity consumed by application logs, databases, and temporary files on a persistent volume. Disk Input/Output (I/O) measures the read and write operational speeds across storage mediums. A database block reading data from a slow mechanical disk or improperly configured cloud storage tier will create an extreme application performance bottleneck.
Network Latency
Network latency measures the duration required for data packets to traverse from a source system to a destination target across network switches, routers, and geographical boundaries. High network latency inside a microservice cluster drastically degrades system performance, as services spend excessive time waiting for downstream API responses over the network.
Monitoring and Observability in DevOps
While beginners frequently use the terms monitoring and observability interchangeably, they represent two distinct levels of operational maturity within systems engineering.
The Three Pillars of Observability
To achieve true system transparency, engineering organizations rely on three essential data types, universally referred to as the three pillars of observability:
- Metrics: Numeric values aggregated over time intervals that tell you what is happening (e.g., “The memory usage on cluster node alpha is currently at 91%”).
- Logs: Plain text records generated by application runtimes or systems that detail why a specific event occurred at a precise timestamp (e.g.,
[2026-06-01 12:00:05] FATAL: Connection refused by PostgreSQL host at 10.0.5.4). - Traces: End-to-end operational maps that follow a single user transaction as it hops through dozens of independent microservices, databases, and third-party APIs, revealing exactly where latency or errors occur during a specific request.
Core Tooling Frameworks
Transforming these data streams into actionable engineering dashboards requires specialized platform stacks.
- Prometheus: An open-source, time-series database engine designed to scrape and store metric telemetry. Prometheus periodically pulls numeric data points from applications using a pull-based architectural model, optimizing it for dynamic cloud-native environments.
- Grafana: A highly customizable open-source visualization analytics platform. Grafana connects directly to data engines like Prometheus, allowing teams to build real-time dashboards containing graphs, heatmaps, and threshold alerts that simplify system status evaluations.
Real-World Example: Team Without Metrics
To fully comprehend the chaos of managing systems without telemetry data, consider the fictional operational workflow of “Team Alpha,” a software engineering group that manages an online ticketing platform without using any DevOps metrics or central observability.
The Guesswork Decisions Workflow
When Team Alpha plans a feature release, their engineering decisions are driven entirely by intuition. The engineering manager guesses that four web servers should be enough to handle a flash holiday ticket sale. There is no historical data or load testing telemetry to back up this assumption.
The Outage and Slow Troubleshooting Narrative
At 10:00 AM, a high-profile concert ticket sale launches. Within three minutes, hundreds of users encounter blank screens and loading spinners. Because Team Alpha does not have real-time dashboards, they are unaware of the failure until angry users start tagging their brand account on social media channels.
The engineering team hops onto an emergency conference call. Without centralized logging or Prometheus metrics, engineers must manually log into individual cloud servers using terminal sessions to run diagnostic commands. One developer guesses the issue is an application bug; another insists the database server has crashed. They spend two hours arguing and reviewing raw file directories across random machines while the site remains completely down.
The Cost of Deployment Failures
Eventually, out of sheer desperation, the team restarts all their server instances simultaneously. The platform slowly recovers, but they have lost thousands of ticket sales, damaged their brand reputation, and have no idea what actually caused the failure. They are trapped in a loop of reactive fire-fighting, terrified of their next major feature deployment.
Real-World Example: Metrics-Driven DevOps Team
Now let us examine “Team Beta,” an engineering organization that manages an identical ticketing platform but operates with an established metrics-driven DevOps culture and a modern monitoring stack.
The Proactive Data Workflow
Before any major ticket sale, Team Beta reviews historical metrics dashboards from their prior quarters. Their Prometheus data clearly shows that user traffic spikes by 800% within sixty seconds of a launch, pushing CPU utilization on their API gateways from 15% to 85%. Armed with this data, they configure automated scaling rules to provision extra compute capacity well ahead of the event.
The Rapid Outage Detection Narrative
When the ticketing launch occurs, a downstream payment gateway provider suddenly experiences an internal network failure. Because Team Beta has an active Grafana dashboard tracking outward-facing HTTP error rates, an automated alert triggers within sixty seconds of the failure, paging the on-call engineer before social media handles even notice a problem.
[TRAFFIC SPIKE] ──> [PAYMENT RETRIES INCREASE] ──> [ALERTS FIRE (60s)] ──> [AUTO-ROUTING ENABLED]
Code language: CSS (css)The on-call engineer checks the Grafana dashboard and observes a sharp spike in HTTP 504 errors originating specifically from the primary payment processor module. Simultaneously, centralized tracing logs point directly to an API connection timeout on that specific vendor’s endpoint.
The Metric-Driven Resolution
Instead of guessing, the team immediately executes a pre-verified configuration change to route checkout traffic to an alternate payment provider. Within five minutes of the initial alert, the error rates drop back to zero, and ticket transactions resume processing normally.
The team finishes the day with record-breaking sales numbers. Later that week, they use their precise system metrics to conduct a blame-free post-mortem analysis, creating permanent engineering fixes to make their platform even more resilient to external vendor failures.
Common Mistakes Teams Make with DevOps Metrics
While tracking data is critical, poorly designed measurement strategies can introduce significant operational friction and team frustration.
Tracking Too Many Metrics
A frequent mistake made by teams starting out is configuring alerts for every single metric available across their systems. This practice leads to severe alert fatigue. When an engineer’s phone triggers fifty non-critical notifications an hour regarding minor, temporary CPU fluctuations, the engineer will eventually mute the alert system entirely, missing critical, high-priority notifications when a production database fails.
Ignoring Business Goals
Engineering metrics must never exist in a technical vacuum. If an infrastructure team spends months optimizing a backend caching pipeline to shave two milliseconds off an internal processing step that has zero impact on user experience or operational costs, they are wasting valuable engineering capital. Metrics should always align with broader business performance goals.
Measuring Without Action
Data collection is completely pointless if the organization lacks the structural willpower or processes required to act on those insights. If a weekly report continuously shows that a team’s Change Failure Rate has risen to a dangerous 35%, yet management refuses to pause feature delivery to address pipeline stability, collecting the metric becomes a bureaucratic, check-the-box exercise.
Using Metrics to Punish Teams
When metrics are transformed into management weapons to penalize developers or rank teams against one another, the cultural foundations of DevOps break down. If developers are punished for having a higher Lead Time for Changes, they will cheat the system by breaking down large, meaningful features into meaningless, microscopic code commits or skipping comprehensive security testing altogether to artificially boost their metrics.
Best Practices for Using DevOps Metrics and KPIs
Building a resilient, sustainable engineering culture requires a structured, intentional approach to system and pipeline measurement.
Start Small
Do not attempt to implement hundreds of custom application dashboards on day one. Focus on the core four DORA metrics first: Deployment Frequency, Lead Time for Changes, Change Failure Rate, and MTTR. Once your organization can reliably track and optimize these four foundational signals, you can safely expand into deeper microservice telemetry.
Focus on Outcomes, Not Output
Ensure your engineering metrics evaluate collective outcomes, such as system availability and deployment stability, rather than individual outputs like lines of code written, tickets closed, or hours spent sitting at a desk. High-quality engineering centers on building elegant, minimal code that solves complex problems reliably.
Review Metrics Regularly
Incorporate metric evaluations directly into your standard team rhythms. Dedicate fifteen minutes during project retrospectives to analyze your pipeline metrics. Review your production incident trends, look for patterns in build failures, and use that concrete historical data to plan your upcoming engineering sprint tasks.
Automate Your Tracking Setup
Never rely on manual spreadsheets or developer self-reporting to track your DevOps metrics. Manual data collection introduces human bias, data entry errors, and unnecessary administrative overhead. Use native integrations within your CI/CD platforms, cloud management systems, and observability tools to gather, compile, and visualize all performance metrics automatically.
The Operational Readiness Checklist
Use this checklist to verify that your metrics strategy is production-ready:
- [ ] Core DORA metrics are calculated automatically by deployment pipelines.
- [ ] Alerting thresholds distinguish clearly between warnings and high-severity incidents.
- [ ] Internal SLOs are documented and understood by both developers and product owners.
- [ ] Dashboards are accessible to the entire engineering team to promote operational transparency.
- [ ] Metrics data is archived for long-term trend analysis and infrastructure planning.
Common Beginner Misunderstandings
When starting out in the DevOps field, it is easy to adopt common myths about metrics that can derail your engineering practices.
Myth 1: More metrics always mean a better DevOps culture
- Reality: Gathering thousands of uncoordinated metrics just creates background noise and confusion. A high-performing engineering team focuses on a concise, highly accurate selection of metrics that directly indicate system health and user experience quality.
Myth 2: KPIs are only useful for executive managers
- Reality: High-level KPIs give developers critical context on how their daily code contributions impact the business. Understanding platform availability goals helps developers make better architectural trade-offs between feature development and system refactoring.
Myth 3: Dashboards and metrics solve problems automatically
- Reality: Monitoring systems can only show you where a failure is occurring; they cannot fix the underlying issue for you. Resolving incidents still requires well-trained, collaborative engineering teams who understand how to debug code and manage infrastructure systems under pressure.
Myth 4: Monitoring only matters within production environments
- Reality: Waiting until code reaches production to monitor its behavior is an expensive mistake. Tracking build times, automated test success rates, and container compile sizes early in development staging pipelines helps you catch performance bottlenecks long before they impact actual customers.
Role of DevOpsSchool in Learning DevOps Monitoring
Mastering the complexities of modern system telemetry, alert orchestration, and infrastructure observability requires guided, practical experience with actual enterprise tools. Conceptual knowledge alone cannot prepare an engineer to resolve a real-time production crisis or optimize a slow corporate release pipeline.
Educational platforms like DevOpsSchool offer comprehensive training programs specifically tailored to close the gap between theoretical DevOps definitions and practical, everyday engineering work. Their learning tracks provide students and working professionals with direct access to live labs, real-world architecture scenarios, and industry-standard monitoring environments.
Through structured courses, learners get hands-on experience setting up full observability pipelines. Students learn exactly how to configure Prometheus to pull custom metrics from web applications, build production-grade Grafana dashboards that map out system performance, write alerting rules that prevent alert fatigue, and interpret complex DORA metric datasets across distributed cloud environments.
By learning to manage software infrastructure through data-driven practices, students develop the practical, reliability-focused mindset required by modern enterprise employers. This hands-on training ensures that when a graduate joins a corporate SRE or platform team, they can confidently navigate real-world monitoring stacks, interpret system metrics accurately, and help their organization deliver stable software upgrades safely.
Career Importance of DevOps Metrics Knowledge
As enterprises worldwide transition away from old legacy deployment models toward highly automated cloud architectures, the demand for tech professionals who understand operational metrics has hit an all-time high.
Role Impact Across Core Positions
- DevOps Engineer: Tracks deployment frequency and pipeline failure rates to remove continuous integration blockages and streamline everyday deployment pipelines.
- Site Reliability Engineer (SRE): Focuses heavily on platform uptime, system error rates, and latency profiles to maintain service health and enforce internal SLO targets.
- Cloud Engineer: Monitors resource consumption patterns like compute capacity and network costs to keep cloud infrastructure runtimes efficient and cost-effective.
- Platform Engineer: Tracks inner-loop development metrics to build highly efficient automated internal developer platforms that help product teams move faster safely.
- Engineering Manager: Evaluates long-term DORA metrics trends to justify resource allocations, balance team workloads, and accurately report delivery health to company executives.
Essential Analytical Skills Needed for Advancement
To advance into senior technical leadership roles, engineering professionals must develop skills beyond just writing script code. They must build strong analytical capabilities, including:
- Advanced Incident Analysis: The ability to trace complex system failures across distributed application logs to find the root cause of an outage.
- Performance Tracking Mastery: Knowing how to systematically isolate and resolve application code latencies using profiling data.
- Reliability Engineering Mindset: Designing proactive defensive systems, such as automated circuit breakers and auto-scaling rules, using real-time system metrics.
Industries Benefiting from DevOps Metrics
Data-driven engineering practices provide significant operational advantages across a wide variety of global commercial verticals.
Banking and Finance
In the fintech space, system downtime can cause millions of dollars in lost transactions and trigger severe regulatory fines. Financial engineering teams track error rates and system availability metrics down to the millisecond, using strict telemetry pipelines to verify that secure transactional networks remain stable under heavy volumes.
Healthcare Platforms
Modern digital medical applications manage sensitive patient health data, electronic records, and real-time telehealth connectivity. Healthcare operations teams track reliability and latency metrics closely to ensure medical professionals have uninterrupted, secure access to critical patient applications during emergencies.
SaaS Platforms
Software-as-a-Service organizations survive based on customer retention and meeting their public service level agreements. By monitoring user-facing response times and application error rates, SaaS businesses ensure their cloud applications scale seamlessly to deliver smooth, high-speed user experiences as their customer base grows.
E-Commerce Systems
Online retail businesses experience massive, highly unpredictable traffic swings during major sales events like Black Friday. E-commerce platforms use infrastructure metrics, checkout success rates, and payment gateway latencies to automatically scale up cloud compute capacity, preventing server crashes during high-volume shopping windows.
Future of DevOps Metrics
As cloud computing platforms evolve, the methods engineering teams use to track, analyze, and act on system telemetry are undergoing a significant technological shift.
[TRADITIONAL MONITORING] [FUTURE OBSERVABILITY]
Manual Dashboards ──────────────> AI-Driven Anomaly Detection
Reactive Alerting ──────────────> Predictive Capacity Planning
Human Triage & Rollback ──────────────> Automated Self-Healing Clusters
Code language: CSS (css)AI-Driven Monitoring and AIOps
The sheer volume of telemetry data generated by modern microservices has grown too large for human engineering teams to audit manually. The future relies heavily on Artificial Intelligence for IT Operations (AIOps). Advanced machine learning algorithms analyze streams of infrastructure logs in real time to automatically discover complex performance anomalies that traditional threshold alerts miss entirely.
Predictive Observability
Instead of simply alerting engineering teams after a database crashes, next-generation monitoring platforms use predictive analytics to spot early signs of impending failure. These tools analyze historical performance trends to warn engineers hours in advance that an application’s storage disk will run out of space or that a memory leak will cause a crash later that evening.
Automated Self-Healing Systems
The industry is moving quickly beyond simple monitoring dashboards toward fully automated, self-healing cloud architectures. In these modern environments, when an observability system detects a spike in error rates caused by a faulty code update, the platform automatically triggers an immediate, safe rollback to the previous stable release version without requiring any human intervention.
FAQs (15 Questions)
1. What are DevOps metrics?
DevOps metrics are the raw, objective technical values collected from software pipelines, testing suites, and production environments. They provide data on system behavior, build durations, and infrastructure health across the software development lifecycle.
2. What is the difference between a metric and a KPI?
A metric is a granular, technical data point focused on system performance (such as memory usage or build time). A Key Performance Indicator (KPI) is a high-level strategic measurement that connects engineering data directly to business outcomes and goals (such as customer-facing uptime or release velocity).
3. What are the four DORA metrics?
The four core DORA metrics are Deployment Frequency, Lead Time for Changes, Change Failure Rate, and Mean Time to Recovery (MTTR). Together, they evaluate an organization’s software delivery speed and pipeline stability.
4. Why is Mean Time to Recovery (MTTR) so important?
MTTR measures an engineering team’s resilience and efficiency in resolving unexpected system outages. A low MTTR demonstrates that an organization has strong automated monitoring, clear alerting pathways, and efficient troubleshooting practices.
5. What does Lead Time for Changes track?
This metric measures the entire time it takes for a code modification to travel from its initial git commit timestamp, through continuous integration testing and staging verification steps, until it successfully runs in production.
6. Can complete beginners understand DevOps metrics easily?
Yes. Beginners can master DevOps metrics by starting with foundational concepts like pipeline build times and server availability before moving on to complex microservice tracking, alerting logic, and full observability platforms.
7. What tools do teams use to monitor DevOps metrics?
Engineering teams rely on open-source and enterprise monitoring stacks, including Prometheus for metrics collection, Grafana for real-time visualization dashboards, along with centralized logging tools to track system health.
8. What is alert fatigue and how do you prevent it?
Alert fatigue occurs when engineers are overwhelmed by a high volume of non-critical, low-priority monitoring alerts. It can be prevented by configuring smart alerting thresholds that focus on actual customer-impacting issues while automating minor infrastructure warnings.
9. What is the difference between monitoring and observability?
Monitoring tells you when a system is failing by tracking predefined metrics thresholds. Observability allows you to understand a system’s internal state from the outside by analyzing its metrics, logs, and distributed traces to diagnose completely new failure patterns.
10. What are SLAs, SLOs, and SLIs?
An SLI is a precise measure of system performance at any given moment. An SLO is the target internal reliability goal agreed upon by engineering and product teams. An SLA is the legally binding performance commitment made to external customers.
11. How does tracking Change Failure Rate improve software quality?
The Change Failure Rate tracks the percentage of production deployments that cause an immediate incident or require a rollback. Monitoring this rate ensures that teams maintain high testing and code quality standards rather than prioritizing deployment speed alone.
12. Why should organizations avoid tracking lines of code written?
Lines of code written is a counterproductive vanity metric that evaluates raw output rather than actual business value. It encourages developers to write bloated, overly complex code, which increases technical debt and system instability.
13. How do infrastructure metrics like CPU and Memory prevent system crashes?
Tracking CPU and memory consumption helps engineering teams spot resource constraints, code inefficiencies, or severe memory leaks early, allowing them to optimize applications or adjust auto-scaling rules before systems become non-responsive.
14. What are the three pillars of observability?
The three pillars of observability are metrics (numeric tracking data), logs (timestamped event text records), and traces (end-to-end flow paths of user transactions through microservices).
15. How does a metrics-driven culture help development teams?
A metrics-driven culture removes guesswork from engineering decisions, reduces finger-pointing during production outages, highlights pipeline friction points, and helps teams continuously improve system reliability using objective data.
Final Thoughts
Building a modern, scalable DevOps practice is a continuous journey of cultural and technical optimization. High-performing engineering groups do not achieve elite status by writing code faster or working longer hours; they succeed by establishing deep operational visibility across their deployment pipelines and cloud infrastructure systems.
Metrics should never be collected just to generate bureaucratic reports or create colorful management dashboards. The true value of telemetry lies in its ability to guide day-to-day engineering actions, inform architectural decisions, and provide early warning signs of system degradation. When teams focus on tracking meaningful metrics like the four DORA indicators and user-facing SLOs, they build a shared culture of transparency and proactive system ownership.
As you continue developing your engineering skills, remember that tracking numbers must always serve a practical purpose: helping your team deliver reliable, stable, and secure software to your users. By utilizing data to guide your development workflows, optimize your infrastructure environments, and eliminate pipeline friction, you can confidently build resilient digital systems that scale effectively to meet long-term enterprise goals.