Source:-computerweekly.com
We look at the basics of creating storage and specifying it for applications in container storage using Kubernetes Persistent Volumes and Persistent Volume Claims
Use of containerised applications, usually with a container orchestrator such as Kubernetes, is currently a huge trend in IT, and is becoming almost ubiquitous with users across all sectors.
Containerised applications is a form of application virtualisation, but one that does away with the need for multiple iterations of an operating system (OS). Containers are something like “traditional” virtual machines (VMs), but make use of the server OS instead of spinning up little versions of their own.
Containers – often Docker, but there are others in the market – contain all that’s needed for an application to run, and can be created, spun up, cloned and scaled, and made extinct very rapidly.
For this reason, containers are well-suited to workloads that see massive spikes in demand, especially on the web, and mainly where Kubernetes’s automation functionality allows this to take place rapidly.
Containers are inherently stateless, and we’ll look at how things work there first, although the bulk of this article will be concerned with persistent storage in Kubernetes, which has become the default container orchestration platform.
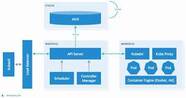
Kubernetes handles functions such as the creation, management, automation, load balancing, relationship to hardware – including storage – of containers, which are organised, in Kubernetes-speak, in pods, which is what we call any collection of one or more containers.
Ephemeral by nature, persistent if needed
At its most basic, storage in Kubernetes is ephemeral (non-persistent). It is storage that is written into the container and created from temporary scratch space on the host machine that exists for the lifespan of the Kubernetes pod. It is created via the emptyDir command and is portable, but not persistent.
Kubernetes also supports persistent storage that can be in a wide range of on-premise and cloud formats, including file, block, object and numerous classes of storage from the cloud providers. Storage can also be in data services, such as databases, which ultimately rely on the existence of physical storage somewhere too.
Storage can be referenced from inside the pod directly, but this is not recommended because it violates the principle of container/pod portability. Instead, persistent volumes and persistent volume claims (PV/PVC) are used to define storage and application requirements.
PVs and PVCs decouple storage implementation from its functioning and allow block/file/object storage to be consumed by a pod in a portable way. They also decouple the needs of the user/application and storage configuration.
A PV is where admins define storage and its performance and capacity parameters – that is, it defines a persistent storage volume. It contains details about the storage such as performance/cost class, capacity, as well as volume plugin used, paths, IP addresses, usernames and passwords and what to do with the volume after use. PVs are not portable across Kubernetes clusters.
Meanwhile, a PVC is used to describe the storage a user/devops wants for their application. These are portable and they travel with the application. Kubernetes works out what storage is available from defined PVs and binds the PVC to it.
PVCs are defined in the pod’s YAML so that the claim travels with it and can be pretty simple, specifying just capacity and tier of storage, for example.
There is provision for multiple cloned pods in Kubernetes, called a deployment, which share a single PVC, but this can lead to problems such as crashes. An alternative is the stateful set, which duplicates PVC across pods.
Storage class groups persistent volumes
A collection of PVs can be grouped in a storage class, which is a Kubernetes application programming interface (API) that setorage parameters. It is a dynamic provisioning method that provides the abilits sty to create new volumes on demand.
Storage class specifies the volume plugin used, the external – eg, cloud – provider and the name of the CSI driver. CSIs – container storage interfaces – are drivers that allow containers to interact with cloud and storage supplier’s products.
It’s good practice to have one storage class marked as “default” so it doesn’t have to be invoked by use of a PVC, or so that it can be invoked if a user doesn’t specify a storage class in a PVC.
A storage class can also be created for old data that may need to be accessed by containerised applications.
Other ways of doing storage in Kubernetes
There are other methods of creating Kubernetes storage but these have their drawbacks, such as lack of portability.
That’s the case for host path, which exposes a directory on the host machine. Obviously that’s not going to be portable because the path will not be accessible if the pod/container moves and it’s not something that most pod deployments will want.
Local persistent volumes can also be created using block, file or object storage. This can be used, for example, to build a distributed storage system on top of Kubernetes, effectively creating a virtualised/containerised storage pool, which is something like what has been created by Rook.