
SRE has been generated in Google Company. It is made of a software engineer’s team, who works with the collaboration between development and operation teams.
The main motive of SRE is to enhance reliability and problem-free function in software. It uses the automation tool to keep the work inflow as well as reduce the toil and remove human errors.
According to 2021 reports, around 22% of organizations have adopted SRE so far. SRE runs with a concept that failure is a software problem, so they run with belief that accepts the failure and work over that to be in reality, because not a single system is perfect.
As SRE has been removed the silos, it works with the collaboration between the development and operation team to enhance the product reliability and to deliver faster services. Monitoring and logging are keys to SRE roles, as monitoring is to keep track of what’s happening in real-time, whereas, Logging is an archive of what has happened, so you can examine it later.
What are SLA, SLO, and SLI in SRE?
Service Level Agreement
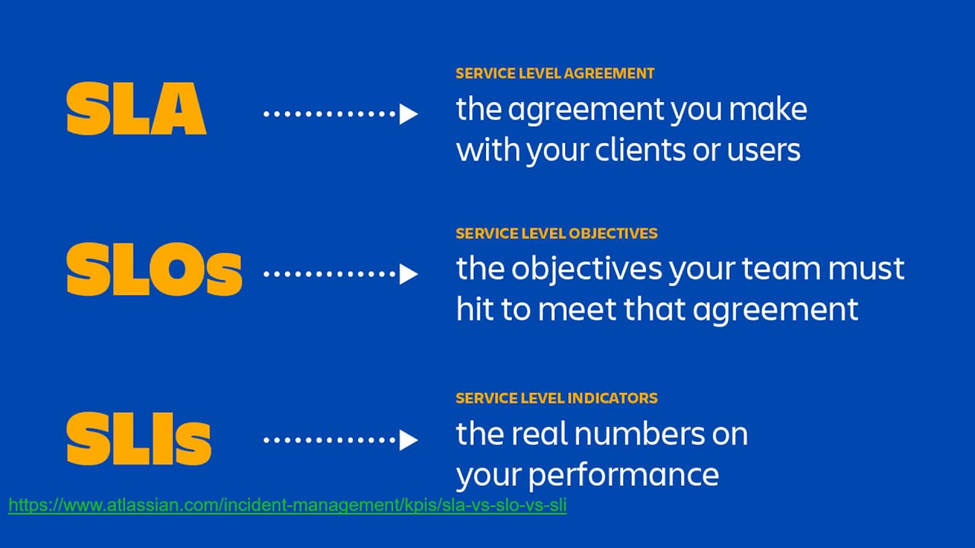
An SLA is an agreement where involves a promise to someone who uses your service, that SLO should meet its availability on a certain level by a certain period and if it fails to make it possible then some kind of penalty will be charged.
In other words, SLA is a Vendor and User agreement and a Customer-centric metric that defines the oblige functionality, performance, and reliability of a product or service and the penalty for non-compliance as well.
It also helps in establishing clarity and trust between the both company and the customer. If the company couldn’t perform the terms agreed in the SLA then it is liable to pay the loss incurred to its customers.
Those companies provide a free service to users, don’t need an SLA.
If SLO is there in your SLA that is different from your internal SLO, it’s important to measure clear-cut SLO compliance for your monitor.
Service Level Objective (SLO).
Service level objectives (SLO) is the one that states a target level for the reliability of the service, as SLO is the key to making data-driven decisions about reliability. These are numerical reliability and performance targets that should be maintained by a developer or an SRE while building and scaling a product. Any changes in the product or service should fall under these defined target values.
SRE starts with the idea that a prerequisite to success is availability. A system that is unavailable can’t perform its function and will fail by default. The term availability in SRE defines whether a system is competent to fulfill its function at the time. Also to be used as a reporting tool, the historical availability measurement can also explain the probability, your system can perform as expected in the future or not.
It’s not possible to manage a service correctly, without understanding what behaviors really matter for that service and how to measure and evaluate those behaviors.
The key to SLOs is simplicity and clarity.
SLA’s are only contingent in the case of paying customers, where SLO’s could be useful for both paid and unpaid accounts, as well as internal and external customers.
SLOs let the IT and DevOps teams as well have a goal or metric to measure their performance.
A service might have more than one SLOs, and they apply to both paying and non-paying customers as well as internal clients in the same organization. For e.g, when a customer-facing team uses tools given by another team within the organization, the two teams need to have clearly defined service level objectives, so the customer-facing teams can meet their contractual obligations.
SLO should be effective, it must not be unclear, complicated, or impossible to measure. The document should contain the relevant SLO’s and be spelled out in plain language to provide clarity. It is also important to keep in mind the other issues like delays from the client.
Service Level Indicator (SLI).
Service Level Indicator (SLI) is a measurement of a service’s behavior, defined as the recap of successful inquiry of our system. To check the SLO availability, we look at SLI to get the service availability percentage. If it goes below the stated SLO, then we will have to make the system more available in some way, such as by running a second occasion of the service in a different city and load-balancing between the two.

SLI is a measure of compliance with an SLO, which means there is no SLI without SLO.
Mostly the SLI directly measures a service level of interest, but sometimes only a proxy is available as the desired measure might be tough to get or explain.
Another kind of importance of SLI to SREs is availability or the fraction of the time when a service is usable.
Since SLIs need to cover the entire terrain of an engineering platform, they can be widely classified into:
- User-interfacing SLIs: All services or applications that the user interacts with within a requests-response. Example – All REST APIs serving web applications, mobile apps, and desktop applications.
- Data-processing SLIs: All services or processes that crunch data on indirect or direct customer requests. Example – Data streaming services, batch applications, ETL tools, event-sourcing services, etc.
Training Place
I would like to tell you about one of the best places to get trained and certification in DevOps, DevSecOps, and SRE courses is DevOpsSchool. This Platform offers the best trainers who have good experience in DevOps and also they provide a friendly eco-environment where you can learn comfortably and free to ask anything regarding your course and they are always ready to help you out whenever you need, that’s why they provide pdf’s, video, etc. to help you.
They also provide real-time projects to increase your knowledge and to make you tackle the real face of the working environment. It will increase the value of yours as well as your resume. So do check this platform if you guys are looking for any kind of training in any particular course and tools.