Source:- infoworld.com
Once upon a time, there was a developer who needed to write code against a database. So he asked the database administrator for access to the production database.
“Oh, dear me, no,” said the DBA. “You can’t touch our data. You need your own database. Ask operations.”
“Oh, dear me, no,” said the operations manager. “We don’t have a spare Oracle license, and it would take six months to get you that and the server on which to run it. But I’ll do what I can.”
You can see where this is going. You can even hear “bwahaha” after each answer. Of course, the DBA and operations manager are only doing their jobs, but the developer – and the needs of the business – are stuck in the slow lane.
What if the developer could have spun up a virtual machine already configured with trial versions of the correct operating system, the correct database, the correct table and index schemas, and syntactically valid test data? And what if all of this happened under the control of a configuration file and scripts while he brewed and drank a cup of coffee? How “agile” would that be?
Enter devops. Basically, devops offers a big box of tools that automate the way around requests that used to result in “no” for an answer. Developers get what they need to do their jobs, and operations can hold up their end of the bargain without too much trouble. These tools can be divided into sets that support each step in the software development lifecycle, from coding to integration to deployment to monitoring to bug reporting.
Developer tools
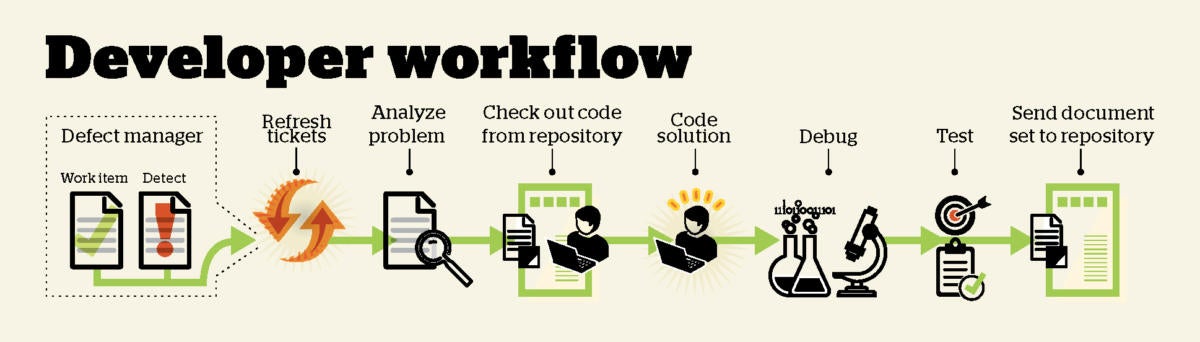
For a developer, working life revolves around a development environment. That has several pieces, which might be integrated or might be a selection of independent tools.
Existing code lives in a repository, such as Git or Team Foundation Server (TFS), and the developer’s first task every day (after the daily stand-up meeting that agile organizations hold first thing) is to check out or clone all of the code of interest from the shared repository. In an ideal world, nobody else’s check-ins or pushes would have an impact on the developer’s code, because everybody’s code would already be merged, integrated, and tested. In the real world, that won’t always be the case, and merging, integrating, and testing yesterday’s changes might be the second order of business.
In an ideal world, all code would be perfect. In the real world, there is no such thing as perfect code – the closest we can come is code that doesn’t have any known bugs.
From the developer’s point of view, looking at the defect manager (be it Bugzilla, JIRA, Redmine, TFS, or any other tracker) and addressing any “tickets” (bug reports or task assignments) is the next order of business.
An IDE such as Eclipse or Visual Studio often has a window into the defect manager, or possibly even deeper ties, but at the very least the developer has a browser tab open to view his or her tickets. The developer will either continue yesterday’s project, or shelve that and handle a higher-priority ticket, if there is one. By the same token, IDEs often integrate tightly with repositories, but at the very least the developer has a command-line console open for check-ins and check-outs. And to complete the triangle, bug trackers often integrate with source code repositories.
The code editor is usually the core component of an IDE. The very best code editors for devops purposes show you the repository status of the code you’re examining, so you can tell immediately if you’re looking at outdated source code. They’ll also refresh your copy before you introduce merge conflicts.
Developers’ build tools depend on the programming language(s) they’re writing in, but in the case of compiled languages, developers want to be able to fire off builds from the IDE and capture the errors and warnings for editing purposes. It also helps if the code editor knows about the syntax of the language, so that it can flag errors in the background during coding and highlight the syntax with colors to help developers visually confirm that, for example, what they intended to be the name of an already-defined variable is correct.
When developers write and test code, they often spend the majority of the day running a debugger. When they are in an organization that has implemented devops, they often have the luxury of debugging in a virtualized environment that faithfully reflects the production environment. Without that, developers may have to use stub code to represent server actions or have local databases stand in for remote databases.
Test runners help developers run their unit tests and regression tests easily and on a regular basis. Ideally, the testing framework integrates with the IDE and any local repository, so that any new code can be tested immediately after check-in, while the developer has the design firmly in mind. The developer’s tests should flow into the code integration environment through the shared repository, along with the source code that the developer has debugged and tested.
Code integration tools
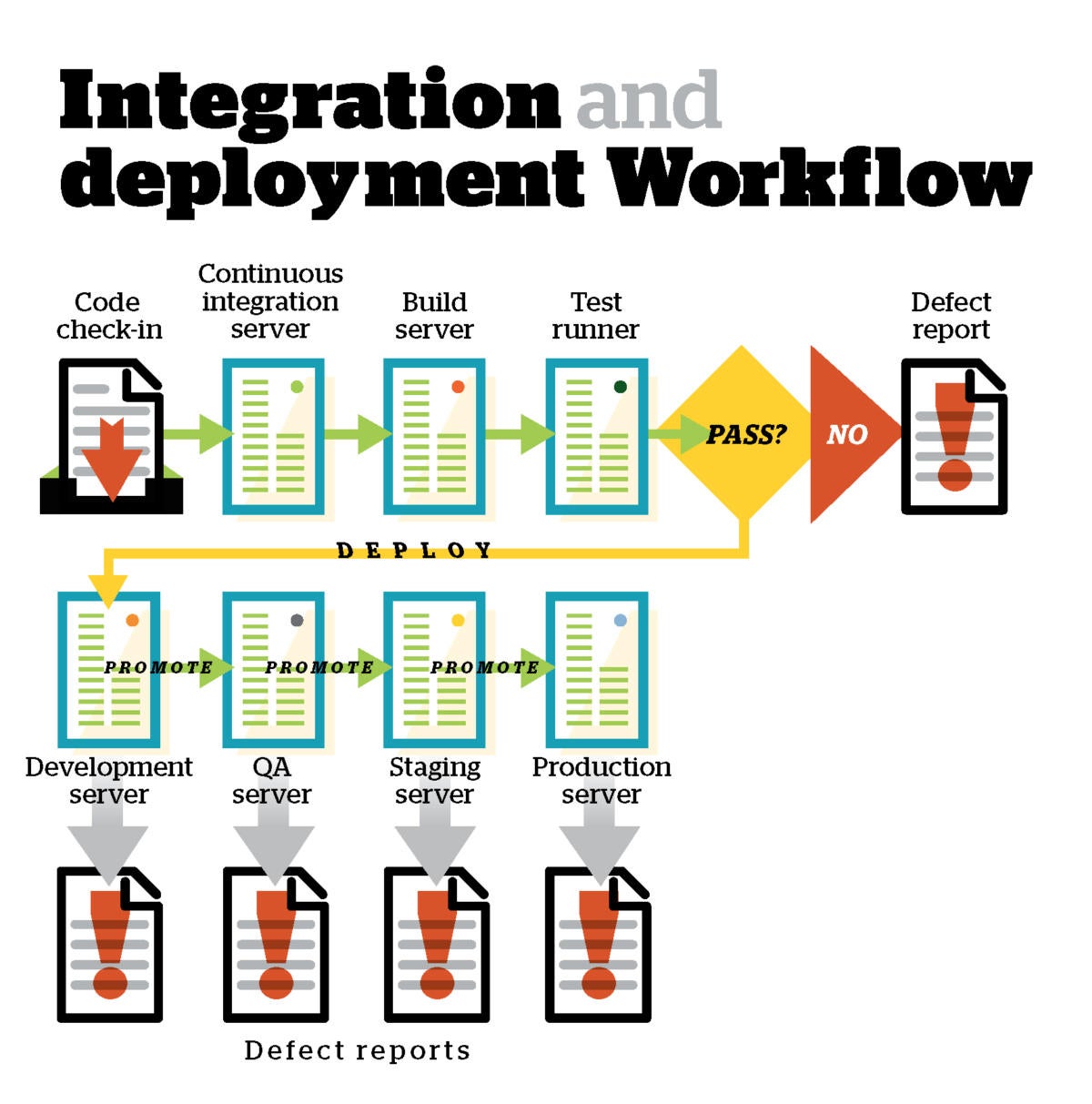
Code integration tools take the code in a shared repository, build it, test it, and report on the results. This is often done using a continuous integration server, such as Jenkins, which will tie into automated build tools, automated test runners, automated reporting via email and defect managers, and actions on the repository.
For example, if the build succeeds and all tests pass, all the current source code and built libraries and executables can be tagged with the current build number in the repository. If critical tests fail, the relevant check-ins can be backed out of the shared repository and returned to the responsible developer(s) for bug fixes.
Some projects implement continuous integration for every code push, if the incremental build time is small. In other projects, a delay is introduced after a code push so that multiple pushes can be combined into the next build. Most projects, whether or not they use automatic builds and tests, and whether or not they integrate after code pushes or on demand throughout the day, also run nightly “clean” builds and tests, often on freshly provisioned test environments.
Deployment tools and environments
If the continuous integration server is set up to deploy builds, after they pass all tests, it will often rely on software deployment and configuration management tools. These often vary depending on the run-time platform and the additional infrastructure.
On the other hand, some configuration management tools – such as Ansible, Chef, Puppet, Salt, and Vagrant – work across a wide range of platforms by using widely supported languages. Ansible and Salt are Python-based systems; Chef, Puppet, and Vagrant are Ruby-based.
Ansible takes recipes in YAML and manages nodes over SSH. Chef uses a Ruby domain-specific language for its configuration recipes and uses an Erlang server as well as a Ruby client.
Puppet uses a custom declarative language to describe system configuration; Puppet usually uses an agent/master architecture for configuring systems, but it can also run in a self-contained architecture. There are more than 2,500 predefined modules listed in the Puppet Forge.
Salt, originally a tool for remote server management, has evolved into an award-winning open source, cloud-agnostic configuration management and remote execution application. Salt can manage and deploy Linux, Unix, Windows, and MacOS systems, and it can orchestrate resources in many clouds. Vagrant is a specialized configuration management tool for development environments that acts as a wrapper for VirtualBox, VMware, and other virtual machine managers. Vagrant takes the sting out of reproducing configuration-dependent bugs.
PaaS (platform as a service) occupies an interesting niche in the cloud ecosystem. It’s basically a dev, test, and deployment platform that sits on top of IaaS (infrastructure as a service). PaaS can be deployed on premises or offered as a service by a public cloud provider. For example, the Pivotal Cloud Foundry PaaS can be deployed on premises on top of VMware’s version of a private cloud, or it can run in a public IaaS cloud such as Amazon EC2.
PaaS includes infrastructure, storage, database, information, and process as a service. Think of PaaS as providing computers, disks, databases, information streams, and business processes or meta-applications, all tied up in one “stack” or “sandbox.” Where a PaaS adds value over IaaS is to automate all of the provisioning of resources and applications, which can be a huge time saver.
There are two kinds of VMs: system VMs, such as VMware, and process VMs, such as the Java Virtual Machine. For the purposes of deployment tools, we are interested in system VMs, in which we can deploy a PaaS, such as Cloud Foundry, or a server application, such as PostgreSQL. In turn, VMs can be deployed on dedicated server hardware, either on-premises or off-premises, or on an IaaS cloud. System VMs offer excellent software isolation, at the expense of incurring some fairly heavyweight hypervisor overhead and using a lot of RAM. Various hypervisors and IaaS infrastructures offer differing amounts of load isolation and differing algorithms for allocating excess CPU capacity to VMs that need it.
Software containers such as Docker offer good-enough software isolation in most cases, with much less overhead than VMs. All PaaS systems with which I am familiar wrap applications in software containers. For example, OpenShift used to run applications in containers called gears, and use SELinux for gear isolation; today it uses Docker as its native container format and runtime. Similarly, Cloud Foundry used to run applications in Warden Linux containers, but has introduced a new container management system, called Diego, that supports Docker and other containers that conform to the Open Container Initiative specification.
On the other hand, Docker can work independently of PaaS systems and can greatly simplify deployment for devops. Docker can make multiple clouds look like one big machine, and it can be used for build automation, continuous integration, testing, and other devops tasks. While Docker began as a Linux-only solution, it recently gained support for Windows as well.
In the grand scheme of a software lifecycle, each feature moves from design to development to testing to staging to production, while bug reports feed back to the developers for triage and fixes at each stage. For products that are released yearly, moving from one stage to another can be a manual process. For agile products that are released weekly or biweekly, release management is often automated. Part of what needs to be automated is the release process management; in addition, teams need to automate their tests, bug tracking, building, packaging, configuration, and promotion processes.
Runtime monitoring tools
Acceptance testing for products usually includes performance testing, which may go all the way up to full-blown load testing with realistic user profiles. Even so, application performance can change in production for a number of reasons: a spike in usage, a memory leak that manifests over time, a bad spot on a disk, an overloaded server, or an ill-considered database index that slows down updates after its underlying table gets big.
Application performance monitoring is intended to continually create metrics for the key performance indicators that matter to your application. These are usually broken down into user metrics, such as time to see a page or complete a transaction, and system metrics, such as CPU and memory utilization. System metrics are typically available all of the time. Passive user metrics, often collected using network monitoring appliances, are of most value when the application is heavily used; active user metrics, collected by generating application requests and measuring the response times, are often reserved for non-peak-load periods.
When your application isn’t performing the way you’d like, determining the root cause may be a frustrating and time-consuming process. Until recently, the DDCM (deep dive component monitoring) agents intended to help you with root cause analysis generated too much overhead to be used in production; you would have to turn them on for a short period to try to capture the problem, then turn them off to allow production to resume at full capacity. In the past couple of years, however, new DDCM products on the market claim to be able to monitor a wide selection of languages and frameworks with minimal overhead, streamlining the root cause analysis process.
Bug reporting and reproduction tools
We mentioned defect managers earlier, but didn’t really elaborate on their use. In a best case, a reported defect will be accompanied by a detailed description, a root cause, a script to reproduce the problem, and it will be assigned to the developer most familiar with the relevant code. In a worst case, a bug report will come from a frustrated user calling into tech support and include a conversation along these lines:
Tech support: What’s wrong?
User: It broke.
Tech support: What were you doing?
User: What I always do. It worked yesterday.
Tech support: Have you changed anything since yesterday?
User: I didn’t change nothin’.
Needless to say, such reports require some skill on the part of tech support to dig out enough of a description and steps to reproduce the problem in order to allow a developer to work on the problem. It may also require remotely entering and running diagnostics on the user’s machine.
Sometimes such problems will not reproduce on a developer’s machine. One common reason for this is that the development box is too fast and has too much memory to show the problem. Another possibility is that the developer has a library installed that the user lacks. And a third is that the user has another application installed that interferes with yours.
Once you’ve determined the user’s runtime environment, the developer can use configuration management tools to create a similar runtime environment in a VM. Vagrant, in particular, is intended for such purposes. The test VM may run locally on the developer’s machine, on a server, or on an IaaS cloud.
In some cases, the steps to reproduce the user’s problem would change the production database. In these situations, it’s useful to have a scaled-down copy of the production application running in a PaaS, so that changes never propagate to the production environment.
Once a fix for the problem is identified and a change set added to the code repository, the revised application must at least be regression tested, and preferably all acceptance tests will be run. If the change is accepted, then the release manager or customer service manager needs to decide whether to propagate the change to production or schedule it for later integration and whether to give the user a patch or an operational work-around.
The never-ending circle
If the modern agile application lifecycle sounds a little like Ezekiel’s vision of a chariot having wheels within wheels, that’s OK: It is. One wheel set represents the sprints – typically one to two weeks – after which an application version is released from development to testing. Another wheel set represents a given build’s climb from development to testing to staging to production. An inner wheel set represents the lifecycle of a story card or application feature. And the tiniest wheels represent bug reports and fixes.
In this complicated environment, development shops can easily bog down at any stage. The purpose of devops is to see that the routine things, such as bringing up a clean test database or promoting a build, are quick and easy, so that the developers can concentrate on building actual features and fixing real bugs.