Source: it.toolbox.com
The latest version of the Cloud Storage Connector for Hadoop gives users increased throughput efficiency for columnar file formats such as Parquet and ORC and performance enhancements, like lower latency, increased parallelization, and intelligent defaults.
Google Cloud Platform recently announced the latest version of the Cloud Storage Connector for Hadoop also called as GCS Connector. Cloud Storage Connector makes it simpler to replace the Hadoop Distributed File System (HDFS) with Cloud Storage.
This new release intends to provide users with amplified throughput efficiency for columnar file formats such as ORC and Parquet, isolation for Cloud Storage directory modifications, and overall significant data workload performance enhancements, for example, increased parallelization, intelligent defaults, and lower latency.
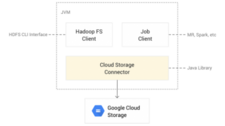
The Cloud Storage Connector is an open-source Java client library that Runs in Hadoop JVMs and permits workloads to access Cloud Storage. The connector lets users big data open-source software [such as Hadoop and Spark jobs, or the Hadoop Compatible File System (HCFS) CLI] read/write data directly.
To Cloud Storage, instead of to HDFS. Storing data in Cloud Storage has several benefits over HDFS:
Significant cost reduction as compared to a long-running HDFS cluster with three replicas on persistent disks;
- Separation of storage from compute, enabling users to grow each layer independently;
- Persisting the storage even after Hadoop clusters are terminated;
- Sharing Cloud Storage buckets between ephemeral Hadoop clusters;
- No storage administration overhead, like enduring upgrades and high availability for HDFS.
The Cloud Storage Connector’s source code is entirely open source and is supported by Google Cloud Platform (GCP). The connector comes pre-configured in Cloud Dataproc, GCP’s managed Hadoop and Spark offering. Though, it is easily installed and fully supported for use in other Hadoop distributions such as Hortonworks, MapR, and Cloudera. This makes it simple to move on-prem HDFS data to the cloud or burst workloads to GCP.
General performance enhancements to Cloud Storage Connector
There are many performance optimizations and improvements in this Cloud Storage Connector release. For example:
- Directory modification parallelization, in addition to using batch request, the Cloud Storage Connector executes Cloud Storage batches in parallel, reducing the rename time for a directory with 32,000 files from 15 minutes to 1 minute, 30 seconds.
- Latency optimizations by decreasing the necessary Cloud Storage requests for high-level Hadoop file system operations.
- Concurrent glob algorithms (regular and flat glob) execution to yield the best performance for all use cases (deep and broad file trees).
- Repair implicit directories during delete and rename operations instead of list and glob operations, reducing the latency of expensive list and glob operations, and eliminating the need for write permissions for read requests.
- Cloud Storage read consistency to allow requests of the same Cloud Storage object version, preventing reading of the different object versions and improving performance