Embracing the principles of chaos engineering in DevOps for production issues
Source:-devopsonline.co.uk
Senior Engineer, Jitander Kapil gives his experience of DevOps as a Service implemented using the Chaos Engineering approach to resolve production issues in a very short time.
Read his insightful case study below to see how he overcame his issues in resolving the conflicts that he encountered and learn more about the benefits of utilising Chaos Engineering for software development and how it can help you to speed up your product development process.
The Challenge
Some months back, I was struggling to Implement DevOps as a Service for Production and UAT issues. As DevOps Leader, my immediate challenge was to implement DevOps practice to resolve any environment and blocking Issues, that was my first and foremost task. This was instead of focusing on engineering practices, Continuous Integration, and Continuous Delivery
Why?
Because DevOps is implemented mostly with Shift Left and for new projects or as part of an Agile/Kanban delivery approach but here the challenge was bringing down production and other environmental issues through DevOps.
The Problem?
There were some time production blockers that had downtimes of 5 minutes to 1 hour, environment issues and blockers.
Sometimes the UAT was down for 30 min or more and there was also the curious case of QA Downtime for up to 4 hours after changes, and infrastructure and N/W chaos.
In this particular case, we had a single delivery pipeline for eight different squads deploying every minute for various technologies and interestingly this was not a new small project, it was a large enterprise system transformation.
The Idea
Chaos Engineering is the idea distributed software systems are prone to experiencing random, turbulent conditions and that you need to investigate unexpected problems and weaknesses in production (or QA/UAT) environments.
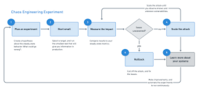
Principle Focus Areas
Chaos in systems requires two groups to control and monitor the activities – an experimental group that experiments (Chaos Teams), and a control group that deals with the effects of experiments (a DevOps team in Phoenix War Room).
Start by defining steady-state as normal behaviour (i.e. PROD/ QA/UAT 24×7 Availability or Zero Down Time).
Four Basic Steps to Perform Chaos Engineering
Team engineers hypothesise an expected outcome when something goes wrong such as Failure Prod Blocker or QA Down
Design an experimental verification approach to debug that reflect events like Environment (QA/UAT) Down, Server Failures/ malfunction, network connections that are severed, etc.
If an engineering team can find weaknesses in the system, then it is a successful chaos experiment, otherwise, they expand their hypothetical boundaries.
When weaknesses are found, the team addresses and fix those issues before they become system-wide troubles.
The Solution is Simple
Implement a policy of using temporary environments for everything, save perhaps the production environment itself.
The goal here is to force your team to develop systems that can instantly and automatically adjust to failures within any and all components.